Porque não posso fazer cross queries entre Azure SQL DBs?
Olá pessoal
Hoje venho com uma dúvida muito comum na comunidade, principalmente para aquelas pessoas que sairam do SQL onPrem e migraram para o Azure, ou aqueles que estão migrando aos poucos. Estava discutindo isso com o meu amigo Leandro Sampaio e disse pra ele que faria um artigo pra explicar algumas possíveis razões de não ser possível realizar consultas . Esse artigo se resume em alguns insigths que tenho do Azure SQL DB e da experiência trabalhando com o mesmo, ainda assim,vou adicionar pontos de como a arquitetura do Azure SQL DB é feita (de acordo com a documentação pública) para que cheguemos o mais próximo do motivo disso não ser possível. Aqui eu não consigo dizer com CERTEZA o motivo, apenas o pessoal que trabalha com o desenvolvimento do produto dentro da Microsoft pode afirmar, no entanto, prometo trazer dados relevantes para chegarmos o mais próximo da verdade possível.
Antes da gente falar do motivo propriamente dito, vamos dar um passo pra trás e rever alguns trechos da documentação pública (trecho de texto e imagens) sobre a arquitetura do Azure SQL DB:
Aqui podemos ver que independente do modo de conexão, o Azure SQL DB possui um “gateway” e um ou N clusters onde os bancos de dados ficam hospedados.
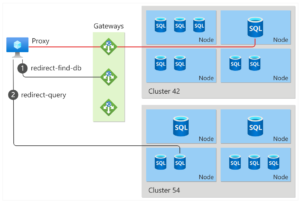
Ainda na parte de logical servers do Azure SQL DB, temos o seguinte trecho:
“In Azure SQL Database and Azure Synapse Analytics, a server is a logical construct that acts as a central administrative point for a collection of databases. At the logical server level, you can administer logins, firewall rules, auditing rules, threat detection policies, and auto-failover groups.This logical server is distinct from a SQL Server instance that you may be familiar with in the on-premises world. Specifically, there are no guarantees regarding location of the databases or dedicated SQL pool in relation to the server that manages them.”
Isso nos diz que, o servidor do Azure SQL database é apenas uma estrutura que serve como ponto de administração de um grupo de banco de dados para alguns itens (login, firewall e etc) e não tem nenhuma GARANTIA da localização dos bancos de dados, sendo assim, pela imagem e a descrição é possível supor que logicamente a Microsoft coloca o servidor sql server, dentro da camada do gateway e ele parece possuir apontamentos para onde o databases estão nas camadas de cluster (42 e 54 na nossa imagem).
Outro fator que eu gostaria de trazer é que, no Azure nós podemos criar diferente databases para um único server(assim como no OnPrem), MAS, mesmo quando eles possuem diferente tiers (basic, standard, premium) para confirmar o que eu estou falando, você pode criar um server com dois bancos de dados sendo um, no BASIC e outro no STANDARD tier . O que isso significa então? Para um mesmo servidor lógico eu posso ter banco de dados com recursos alocados diferentes, sendo assim, eles não podem fazer parte do mesmo servidor físico. Olhando novamente na nossa imagem, faz parecer que cada database vai para um nó diferente dentro do mesmo cluster.
Cada database parecer tem seu próprio usuário (assim como no on-prem um login vira um user quando atribuido para a base, mesmo quando o login é o mesmo, cada BASE TEM SEU USUÁRIO), o que parece que acontece aqui é que a autenticação SEMPRE vai ter que passar no SERVER (gateway)
Mas como isso é possível, o SQL não fica em um único cluster? Ainda dando alguns passos pra trás, vamos para outro conceito muito importante no Azure que é o service fabric.
O que é o Azure Service Fabric?
O Azure Service Fabric é uma plataforma de computação distribuída desenvolvida pela Microsoft como parte do ecossistema do Microsoft Azure. Ele fornece um conjunto de ferramentas e serviços para criar, implantar e gerenciar aplicativos altamente escaláveis, resilientes e de alto desempenho em ambientes de nuvem, local ou híbridos.
O Azure Service Fabric é baseado em uma arquitetura de microservices, que é um padrão de projeto de software em que os aplicativos são divididos em componentes independentes e escaláveis, chamados de microservices, que se comunicam entre si por meio de protocolos leves, como HTTP ou TCP/IP. O Service Fabric oferece recursos avançados para gerenciar a implantação, atualização, escalonamento e monitoramento de microservices, tornando mais fácil criar aplicativos distribuídos e de alta disponibilidade.
O Azure Service Fabric também suporta a criação de aplicativos stateful, ou seja, aplicativos que mantêm informações de estado em vez de serem completamente stateless. Ele fornece recursos de gerenciamento de estado, como replicação, particionamento e gerenciamento de falhas, para garantir a confiabilidade e a disponibilidade de aplicativos que requerem armazenamento persistente de dados.
Além disso, o Azure Service Fabric é uma plataforma flexível que pode ser usada para criar uma ampla variedade de aplicativos, incluindo aplicativos web, aplicativos de análise de dados em tempo real, aplicativos de IoT (Internet das Coisas), jogos online, aplicativos de e-commerce e muitos outros.
Em resumo, o Azure Service Fabric é uma plataforma de computação distribuída que facilita a criação, implantação e gerenciamento de aplicativos escaláveis e de alta disponibilidade, baseados em microservices, no ecossistema do Microsoft Azure.
Mas quem disse que o Azure SQL DB usa o “tal do Fabric”? Resposta, a própria documentação pública do Service Fabric
“Focus on building applications and business logic, and let Azure solve the hard distributed systems problems such as reliability, scalability, management, and latency. Service Fabric is an open source project and it powers core Azure infrastructure as well as other Microsoft services such as Skype for Business, Intune, Azure Event Hubs, Azure Data Factory, Azure Cosmos DB, Azure SQL Database, Dynamics 365, and Cortana. Designed to deliver highly available and durable services at cloud-scale, Azure Service Fabric intrinsically understands the available infrastructure and resource needs of applications, enabling automatic scale, rolling upgrades, and self-healing from faults when they occur.”
O que sabemos até agora:
- O servidor do SQL DB é apenas lógico
- Podemos bancos em diferentes tiers no mesmo server
- O Azure SQL DB usa o Service Fabric
- Os bancos ficam em nós separados e cada um tem seu usuário
- Que um Service Fabric é um CLUSTER
- Se eu tenho um server no GATEWAY e o SQL DB usa o SERVICE Fabric, faz sentido o GATEWAY também ser um cluster de Service Fabric
- O gateway nós chamamos de CONTROL RING e o cluster de TENANT RING (connect com os dois modos no azure sql db proxy e redirect de dentro e fora do Aure e você vai entender)- OBS – Talvez faça um artigo sobre isso ou coloque no meu curso de Azure SQL DB.
Baseado nas coisas que assumi nos bullets acima, imagino a arquitetura mais o menos asssim:
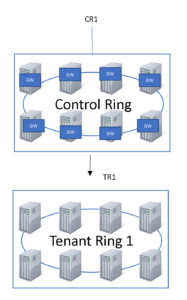
Sendo assim, chego algumas possíveis conclusões o motivo de não ser possível usar CROSS QUERY in AZURE SQL DB, sendo eles:
- Se eu tenho um database em cada nó, eu iria precisar de um linked server pra realizar cross query. Isso deixaria minha performance não muito boa além de outros fatores que poderia trazer problema rodando em uma arquitetura de service fabric.
- Como cada Azure SQL DB pode ser hospedado em uma instancia diferente and não há garantia que o DB vão estar no mesmo node (Service Fabric things) and não podemos simplesmente passar as credenciais do usuário entre instâncias (isso mesmo, cada node, uma instância), pois, isso seria uma violação direta do principio de ambiente multi tenant
Isso vai ser uma limitação para sempre? Possivelmente não, pois, já temos o Elastic Query que resolve o nosso problema, ainda em preview.
Espero que tenham gostado e é isso ai, te vejo na próxima
Muito Obrigado