Desmitificando locks no SQL Server
Olá pessoal, espero que estejam bem. Hoje gostaria de falar de um assunto que as vezes é muito discutido e gera dúvidas dos iniciantes de banco de dados e até mesmo entre DBAs no nível pleno/senior para entender com clareza alguns conceitos que faltam no dia a dia. Se você não leu meu primeiro artigo quando voltei a escrever no meu blog, vai perceber que estou focado em cobrir coisas do básico ao avançado com conceitos.
O assunto que irei apresentar hoje tem muita informação na internet, mas, aqui no meu blog quero montar uma ordem cronológica e muito bem explicada para que os artigos se transforme em um “play book” pra você e, esse blog não se trata do que já escreveram na internet, mas, o que de fato acho que é importante para você DBA (os aspirante a DBA) pra se tornar um DBA que possui os conceitos para explicar o que você faz hoje. O que será abordado nesse artigo:
- Conceitos ACID
- Locks no SQL Server
- Diferença de locks, bloqueios e deadlocks
- Vantagens de locks
- Tipos de Locks
- Hierarquia de locks
- Demonstração
O que será coberto em outro momento:
- Como o SQL server escolhe colocar os locks
- Nível de isomalento do SQL Server
- Compatibilidade de locks
- Hints que podemos usar para influenciar o SQL Server
- Deadlocks no SQL Server
O que é o conceito de ACID para banco de dados sql server?
Não te como falar de locks no SQL Server ou em qualquer banco de dados sem falar de ACID. O conceito ACID é um conjunto de propriedades que garantem a consistência e a confiabilidade dos dados em um banco de dados, independentemente de quaisquer falhas ou interrupções que possam ocorrer. ACID é uma sigla para Atomicidade, Consistência, Isolamento e Durabilidade (em inglês, Atomicity, Consistency, Isolation, Durability), uma breve descrição desses termos:
- Atomicidade (Atomicity): A atomicidade garante que todas as operações realizadas em um banco de dados sejam tratadas como uma única unidade atômica. Isso significa que, se uma operação falhar ou for interrompida no meio do processo, todas as operações relacionadas serão revertidas para garantir que o banco de dados não fique em um estado inconsistente.
- Consistência (Consistency): A consistência garante que todas as operações realizadas em um banco de dados sigam as regras e restrições definidas, garantindo que o banco de dados sempre permaneça em um estado válido e consistente.
- Isolamento (Isolation): O isolamento garante que as operações em um banco de dados sejam executadas independentemente umas das outras, sem interferência ou conflito. Isso significa que mesmo que várias transações estejam ocorrendo simultaneamente, cada uma delas deve ser tratada como se fosse a única transação em andamento.
- Durabilidade (Durability): A durabilidade garante que todas as operações realizadas em um banco de dados sejam permanentes, mesmo em caso de falha ou interrupção. Isso significa que, uma vez que uma operação tenha sido concluída com sucesso, ela deve ser armazenada de forma permanente no banco de dados e não pode ser desfeita.
Em resumo, o conceito ACID é um conjunto de propriedades que garantem a integridade e a confiabilidade dos dados em um banco de dados SQL Server, independentemente de quaisquer falhas ou interrupções que possam ocorrer.
O que são locks no SQL Server ?
Locks no SQL Server são mecanismos (uma estrutura em memória,não o hekaton, mas, “algo” que faz parte do BP (buffer pool) do SQL Server) usados para controlar o acesso concorrente aos dados em um banco de dados. Quando um usuário ou uma transação acessa um determinado recurso (como uma tabela ou uma linha de uma tabela), um lock é colocado nesse recurso para garantir que nenhum outro usuário ou transação possa modificá-lo ao mesmo tempo.
Qual a diferença entre locks, bloqueios e deadlocks no SQL Server ?
Ainda não vamos falar sobre deadlocks, irei escrever um artigo apenas pra tratar disso, mas, nesse momento é importante entender essa diferença dos termos supracitados para não confundir os conceitos e não achar que o deadlock é um lock e que um bloqueio é a mesma coisa que um lock.
Locks e bloqueios são termos frequentemente usados de forma intercambiável, mas no contexto do SQL Server eles têm significados ligeiramente diferentes, preste atenção no “ligeiramente”.
- Locks, referem-se aos mecanismos usados pelo SQL Server para controlar o acesso concorrente aos dados em um banco de dados. Quando um usuário ou uma transação acessa um recurso, como uma tabela ou uma linha de tabela, um lock é colocado no recurso para garantir que nenhum outro usuário ou transação possa modificá-lo ao mesmo tempo.
- Bloqueios (ou bloqueios prolongados) referem-se a situações em que uma transação adquiriu um lock em um recurso e não o liberou imediatamente, impedindo que outros usuários ou transações acessem o recurso. Isso pode levar a problemas de desempenho e afetar a capacidade do sistema de processar outras transações.
- Deadlocks (interbloqueios) ocorrem quando duas ou mais transações estão aguardando locks para acessar recursos diferentes e estão bloqueando umas às outras, impedindo que qualquer uma delas prossiga. Isso pode levar a uma situação em que nenhuma transação pode ser concluída e é necessário o cancelamento de pelo menos uma delas para permitir que as outras prossigam.
Resumindo, os locks são os mecanismos usados para controlar o acesso concorrente aos dados, os bloqueios são situações em que uma transação adquiriu um lock e não o liberou imediatamente, e os deadlocks ocorrem quando duas ou mais transações estão bloqueando umas às outras e impedindo que qualquer uma delas prossiga. O SQL Server possui mecanismos para detectar e resolver deadlocks, como o mecanismo de deadlock detection e o recurso de timeout para liberar bloqueios prolongados.
Porque o SQL Server utiliza locks e qual a vantagem disso?
O SQL Server utiliza locks para controlar o acesso concorrente aos dados em um banco de dados. Quando vários usuários ou transações acessam o mesmo recurso (como uma tabela ou uma linha de tabela) simultaneamente, os locks são usados para garantir que cada usuário ou transação possa acessar o recurso de forma segura e consistente, sem interferência ou conflito com outros usuários ou transações.
A principal vantagem do uso de locks no SQL Server é que eles garantem a consistência e a integridade dos dados em um ambiente de múltiplos usuários e transações concorrentes. Sem locks, os usuários ou transações que tentam acessar os mesmos dados simultaneamente podem causar conflitos e inconsistências nos dados. Por exemplo, se duas transações tentarem atualizar a mesma linha de uma tabela simultaneamente, sem locks, uma transação pode substituir os dados atualizados pela outra transação, causando a perda de dados e a inconsistência dos dados.
Os locks permitem que vários usuários ou transações acessem os mesmos dados simultaneamente, desde que não haja conflitos entre as operações realizadas. Por exemplo, vários usuários podem ler os mesmos dados simultaneamente, sem interferência entre eles, mas se um usuário tentar atualizar os dados, um lock exclusivo será colocado para impedir que outros usuários modifiquem os dados ao mesmo tempo.
Em resumo, a utilização de locks no SQL Server é essencial para garantir a consistência e a integridade dos dados em um ambiente de múltiplos usuários e transações concorrentes.
Percebeu porque o conceito do ACID é importante aqui? Esse conceito é empregado na maioria (se não em todos) os SGBDs, por isso importante saber esse tipo de conceito, pois, quando você dominar isso, o banco de dados que você usa será apenas uma ferramenta e você pode se sentir confortável em aprender um segundo de maneira mais eficiente.
Quais são os tipos de lock no SQL Sever ?
No SQL Server, existem diferentes tipos de locks que podem ser usados para controlar o acesso concorrente aos dados em um banco de dados. Abaixo estão os principais tipos de locks disponíveis no SQL Server:
- Shared locks (S): Também conhecidos como locks de leitura, permitem que várias transações leiam um recurso ao mesmo tempo, mas impedem que outras transações o modifiquem enquanto o lock estiver ativo.
- Update locks (U): Também conhecidos como locks de atualização, são usados para impedir que outras transações atualizem um recurso ao mesmo tempo em que uma transação está atualizando-o. Update locks são compatíveis com outros shared locks, o que significa que outras transações ainda podem ler o recurso enquanto um update lock está ativo.
- Exclusive locks (X): Também conhecidos como locks de escrita, impedem que outras transações acessem ou modifiquem um recurso enquanto um lock exclusivo está ativo. Os exclusive locks são incompatíveis com todos os outros tipos de locks.
- Intent locks: São locks que são colocados em níveis mais altos de hierarquia para indicar que um recurso está sendo usado por uma transação. Eles indicam a intenção de um processo de adquirir locks de compartilhamento (shared locks), locks de atualização (update locks) ou locks exclusivos (exclusive locks) no recurso de nível inferior. Esses locks servem pra avisar o seguind para o mecanismo de lock o SQL :“Ei , se você quiser colcar um lock exclusivo aqui, perceba que eu tenha a intenção de fazer uma alteração em algum recurso dessa página, sendo assim, você não pode monopolizar toda essa página devido a minha intenção”.
- Schema locks: São locks que protegem um objeto de banco de dados para alterações de esquema, como renomear ou excluir o objeto.
- Bulk update locks: São locks de atualização especiais usados em operações de bulk, como BULK INSERT, UPDATE BULK e DELETE BULK. Eles são mais restritivos do que os update locks regulares e podem bloquear uma tabela inteira durante uma operação de bulk.
- Key-range locks: São locks que protegem um intervalo de valores em um índice de uma tabela, garantindo que nenhuma outra transação possa inserir, atualizar ou excluir um valor que esteja dentro desse intervalo.
Ainda não iremos falar a granularidade e de como os tipos de locks interagem entre si, mas, também iremos ver isso por aqui.Mas, em resumo o SQL Server oferece diferentes tipos de locks que podem ser usados para controlar o acesso concorrente aos dados em um banco de dados, dependendo da natureza da operação e da necessidade de exclusividade do recurso.
Hierarquia de locks on SQL Server
No SQL Server, a hierarquia de locks é baseada na estrutura de objetos do banco de dados, com locks de nível inferior sendo protegidos por locks de nível superior. A hierarquia de locks é importante porque permite que um processo adquira um lock de nível superior que cubra um recurso inteiro em vez de ter que adquirir locks individuais em cada parte do recurso. A hierarquia de locks no SQL Server é geralmente organizada da seguinte forma:
- Locks em objetos: São locks que protegem objetos de banco de dados, como tabelas, índices, procedimentos armazenados, entre outros. Eles são o nível mais alto de locks e cobrem todo o objeto.
- Locks em páginas: São locks que protegem as páginas físicas no disco que contêm os dados do objeto. Cada página pode ser compartilhada por várias transações, mas apenas uma transação pode modificar a página ao mesmo tempo.
- Locks em linhas: São locks que protegem linhas individuais de uma tabela. Row locks são usados principalmente para minimizar o tempo de bloqueio e permitir o acesso concorrente aos dados.

OBS – Não iremos cobrir lock de partição aqui, até falarmos de particionamento, pois, isso será tratado em um outro artigo.
A hierarquia de locks no SQL Server é dinâmica e pode mudar dependendo do tipo de operação sendo executada e dos recursos envolvidos. Por exemplo, se uma transação estiver lendo um conjunto de dados em uma tabela, o SQL Server pode optar por usar locks de nível de página para otimizar o desempenho. No entanto, se a mesma transação estiver atualizando os dados, o SQL Server pode optar por usar locks de nível de linha para garantir a consistência dos dados. No fim, a hierarquia de locks no SQL Server é uma estrutura de camadas que protege os objetos de banco de dados em diferentes níveis, desde objetos de banco de dados inteiros até linhas individuais em uma tabela. O SQL Server usa locks de nível superior para cobrir um recurso inteiro e locks de nível inferior para proteger partes específicas do recurso.
Mas, como o SQL Server coloca esses locks e como podemos ver isso na prática? Vamos a nossa demo.
Primeiro criamos o nosso setup, para isso estou usando um banco de dados Northwind, você pode rodar esse script em qualquer banco de dados, até mesmo no master (não é uma boa prática ter objetos de usuários em bancos de dados de sistema).
Eu rodei esse script no meu SQL Server 2017, mas, deveria funcionar na maioria das novas versões (devido a syntax values (bla bla), (bla bla). Vamos criar o nosso banco e inserir alguns registros.
|
1 2 3 4 5 6 7 8 9 |
--Set up do ambiente de demo USE Northwind GO --Cria a tabela de cliente, com algumas propriedades CREATE TABLE Cliente(CodCli int identity not null primary key, PrimeiroNome varchar(20) , UltimoNome varchar(80)) --Insere alguns registros INSERT INTO Cliente(PrimeiroNome,UltimoNome) VALUES ('Thiago','Alencar'),('Bianca','Alencar'),('Adriano','Valadao'), ('Andressa','Valadao'), ('Leonardo','Alencar'), ('Felipe', 'Castro') |
Mostra os arquivos que foram inseridos com o comando SELECT * FROM Cliente
|
1 2 |
--Mostra os dados que foram inseridos SELECT * FROM Cliente |
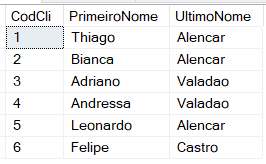
Obs – Evite usar “*”, isso é apenas para propósito de demo.
Vamos rodar o script na mesma sessão que você rodou os scripts acima ou em uma outra sessão. O objetivo é executar um comando de update mudando o no sobrenome do Thiago (pelo código que é a primary key da tabela) de Alencar para Uzumaki, percebam que eu não “comitei” propositalmente para que quando a gente lê esse registro de uma otura sessão, a gente gere um bloqueio
|
1 2 3 |
--Rodar na sessão 1 BEGIN TRAN --Abre uma transação UPDATE Cliente SET UltimoNome = 'Uzumaki' WHERE CodCli = 1 |
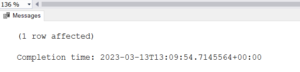
Uma linha foi afetada (CodCli = 1)
Em uma segunda sessão, vamos tentar ler o mesmo registro pela PK, sem usar hints ou qualquer ajuste (isso também vai ser explicado em outro artigo)
|
1 2 |
--Rodar na sessão de número dois, ler o cliente que que atualizamos anteriormente SELECT * FROM Cliente WHERE CodCli=1 |
Você vai perceber que essa sessão vai ficar bloqueada, pois, por padrão o SQL Server (onprem) só ler dados que já foram comitados (após o commit) e eu não fechei o meu update na outra sessão.
Em uma terceira sessão, nós vamos executar o select na view de sistema sys.dm_tran_locks (vamos fazer uma sessão de artigos apenas pra falar de DMVs, eita, muito assunto que temos que cobrir) e interpretar os dados. Vamos focar na sessão 65, que foi a sessão que ficou bloqueada.
|
1 2 |
--Faz o select na sys.dm_tran_locks SELECT * FROM sys.dm_tran_locks where resource_database_id= 12 |

Podemos ver que, a sessão 65 tem mais do que um lock, quatro no total, mas, ele está em diversos níveis (hierarquia como já explicado). Perceba que com exceção do lock em nivel de linha (linha 7 na imagem), todos foram “permitidos” pela engine de lock do SQL Server. O que podemos dizer aqui? A sessão 65 requisitou um lock de leitura (request_mode = S, devido ao select que rodamos) e no nível de linha (KEY na coluna resource_type) ele está aguardando (status WAIT na coluna request_status) o mesmo ser liberado, que está aguardando nosso UPDATE na sessão 52.Todos os demais locks foram “permitidos”, mas, não significa que eles de fato serão permitidos, pois, o SQL Server tem um lock exclusivo permitido (GRANT na coluna reques_status) na linha 6 da nossa imagem e temos a intenção (IX) de modificá-los em um nível acima (PAGE na linha 5 do nosso print com status_mode IX), isso avisa as demais sessões/ transações que, caso quiserem alterar essa página, existe alguém que já tem um lock em um recurso dela (linha 6 do print), mas, está permitido a leitura (IS) no nível de objeto, página e até mesmo no banco de dados (linha 8, linha 4, linha 1 e 2 respectivamente).
Conclusão
Nesse artigo vimos como o SQL Server coloca os locks em nossos recursos e sua hierarquia pra fazer isso, também conhecemo uma nova DMv (sys.dm_tran_locks) que mostra toda essa hierarquia.
Espero que tenha gostado e, espero ver vocês aqui na próxima, compartilhem e mande suas dúvidas. “Stay tuned”
Abs do TC